
7. sharding-jdbc源码之group by结果合并(2)
阿飞Javaer,转载请注明原创出处,谢谢!
在sharding-jdbc源码之group by结果合并(1)中主要分析了sharding-jdbc如何在GroupByStreamResultSetMerger和GroupByMemoryResultSetMerger中选择,并分析了GroupByStreamResultSetMerger的实现;接下来分析GroupByMemoryResultSetMerger的实现原理;
通过sharding-jdbc源码之group by结果合并(1)的分析可知,如果要走GroupByMemoryResultSetMerger,那么需要这样的SQL:SELECT o.status, count(o.user_id) count_user_id FROM t_order o where o.user_id=10 group by o.status order by count_user_id asc,即group by和order by的字段不一样;接下来的分析都是基于这条SQL;
ExecutorEngine.build()方法中通过return new GroupByMemoryResultSetMerger(columnLabelIndexMap, resultSets, selectStatement);调用GroupByMemoryResultSetMerger,GroupByMemoryResultSetMerger的构造方法源码如下:
public GroupByMemoryResultSetMerger(
final Map<String, Integer> labelAndIndexMap, final List<ResultSet> resultSets, final SelectStatement selectStatement) throws SQLException {
// labelAndIndexMap就是select结果列与位置索引的map,例如{count_user_id:2, status:1}
super(labelAndIndexMap);
// select查询语句
this.selectStatement = selectStatement;
// resultSets就是并发在多个实际表执行返回的结果集合,在多少个实际表上执行,resultSets的size就有多大;
memoryResultSetRows = init(resultSets);
}
在实际表t_order_0和t_order_1上执行SQL返回的结果如下:
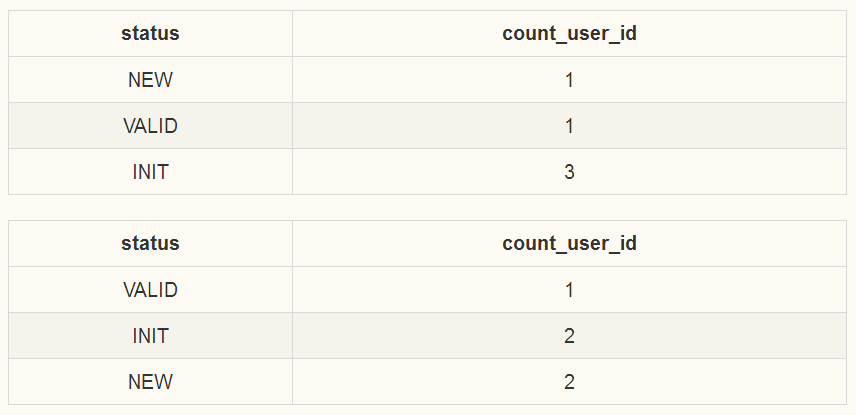

t_order_0和t_order_1结果.png
知道实际表的返回结果后,后面的分析更容易理解;假定这些返回结果用json表示为:{[{"status":"NEW", "count_user_id":1},{"status":"VALID", "count_user_id":1},{"status":INIT, "count_user_id":2}],[{"status":"VALID", "count_user_id":1},{"status":"INIT", "count_user_id":1},{"status":""NEW, "count_user_id":3}]}
init()方法源码如下:
private Iterator<MemoryResultSetRow> init(final List<ResultSet> resultSets) throws SQLException {
Map<GroupByValue, MemoryResultSetRow> dataMap = new HashMap<>(1024);
Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap = new HashMap<>(1024);
// 遍历多个实际表执行返回的结果集合中所有的结果,即2个实际表每个实际表3条结果,总计6条结果
for (ResultSet each : resultSets) {
while (each.next()) {
// each就是遍历过程中的一条结果,selectStatement.getGroupByItems()即group by项,即status,将结果和group by项组成一个GroupByValue对象--实际是从ResultSet中取出group by项的值,例如NEW,VALID,INIT等
GroupByValue groupByValue = new GroupByValue(each, selectStatement.getGroupByItems());
// initForFirstGroupByValue()分析如下
initForFirstGroupByValue(each, groupByValue, dataMap, aggregationMap);
aggregate(each, groupByValue, aggregationMap);
}
}
// 将aggregationMap中的聚合计算结果封装到dataMap中
setAggregationValueToMemoryRow(dataMap, aggregationMap);
// 将结果转换成List<MemoryResultSetRow>形式
List<MemoryResultSetRow> result = getMemoryResultSetRows(dataMap);
if (!result.isEmpty()) {
// 如果有结果,再将currentResultSetRow置为List<MemoryResultSetRow>的第一个元素
setCurrentResultSetRow(result.get(0));
}
// 返回List<MemoryResultSetRow>的迭代器,后面的取结果,实际上就是迭代这个集合;
return result.iterator();
}
initForFirstGroupByValue()源码如下:
private void initForFirstGroupByValue(final ResultSet resultSet, final GroupByValue groupByValue, final Map<GroupByValue, MemoryResultSetRow> dataMap,
final Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap) throws SQLException {
// groupByValue如果是第一次出现,那么在dataMap中初始化一条数据,key就是groupByValue,例如NEW;value就是new MemoryResultSetRow(resultSet),即将ResultSet中的结果取出来封装到MemoryResultSetRow中,MemoryResultSetRow实际就一个属性Object[] data,那么data值就是这样的["NEW", 1]
if (!dataMap.containsKey(groupByValue)) {
dataMap.put(groupByValue, new MemoryResultSetRow(resultSet));
}
// groupByValue如果是第一次出现,那么在aggregationMap中初始化一条数据,key就是groupByValue,例如NEW;value又是一个map,这个map的key就是select中有聚合计算的列,例如count(user_id),即count_user_id;value就是AggregationUnit的实现,count聚合计算的实现是AccumulationAggregationUnit
if (!aggregationMap.containsKey(groupByValue)) {
Map<AggregationSelectItem, AggregationUnit> map = Maps.toMap(selectStatement.getAggregationSelectItems(), new Function<AggregationSelectItem, AggregationUnit>() {
@Override
public AggregationUnit apply(final AggregationSelectItem input) {
// 根据聚合计算类型得到AggregationUnit的实现
return AggregationUnitFactory.create(input.getType());
}
});
aggregationMap.put(groupByValue, map);
}
}
该方法都是为了接下来的聚合计算做准备工作;
aggregate()源码如下–即在内存中将多个实际表中返回的结果进行聚合:
private void aggregate(final ResultSet resultSet, final GroupByValue groupByValue, final Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap) throws SQLException {
// 遍历select中所有的聚合类型,例如COUNT(o.user_id)
for (AggregationSelectItem each : selectStatement.getAggregationSelectItems()) {
List<Comparable<?>> values = new ArrayList<>(2);
if (each.getDerivedAggregationSelectItems().isEmpty()) {
values.add(getAggregationValue(resultSet, each));
} else {
for (AggregationSelectItem derived : each.getDerivedAggregationSelectItems()) {
values.add(getAggregationValue(resultSet, derived));
}
}
// 通过AggregationUnit实现类即AccumulationAggregationUnit进行聚合,实际上就是聚合本次遍历到的ResultSet,聚合的临时结果就在AccumulationAggregationUnit的属性result中(AccumulationAggregationUnit聚合的本质就是累加)
aggregationMap.get(groupByValue).get(each).merge(values);
}
}
经过for (ResultSet each : resultSets) { while (each.next()) { ... 遍历所有结果并聚合计算后,aggregationMap这个map中已经聚合计算完后的结果,如下所示:
{
"VALID": {
"COUNT(user_id)": 2
},
"INIT": {
"COUNT(user_id)": 5
},
"NEW": {
"COUNT(user_id)": 3
}
}
再将aggregationMap中的结果封装到Map<GroupByValue, MemoryResultSetRow> dataMap这个map中,结果形式如下所示:
{
"VALID": ["VALID", 2],
"INIT": ["INIT", 5],
"NEW": ["NEW", 3]
}
MemoryResultSetRow的本质就是一个
Object[] data,所以其值是["VALID", 2],["INIT", 5]这种形式
将结果转成List<MemoryResultSetRow>,并且排序–如果有order by,那么根据order by的值进行排序,否则根据group by的值排序:
private List<MemoryResultSetRow> getMemoryResultSetRows(final Map<GroupByValue, MemoryResultSetRow> dataMap) {
List<MemoryResultSetRow> result = new ArrayList<>(dataMap.values());
Collections.sort(result, new GroupByRowComparator(selectStatement));
return result;
}
@RequiredArgsConstructor
public final class GroupByRowComparator implements Comparator<MemoryResultSetRow> {
private final SelectStatement selectStatement;
@Override
public int compare(final MemoryResultSetRow o1, final MemoryResultSetRow o2) {
if (!selectStatement.getOrderByItems().isEmpty()) {
return compare(o1, o2, selectStatement.getOrderByItems());
}
return compare(o1, o2, selectStatement.getGroupByItems());
}
...
}
到这里,GroupByMemoryResultSetMerger即内存GROUP聚合计算已经分析完成,依旧通过运行过程图解加深对GroupByMemoryResultSetMerger的理解,运行过程图如下图所示:
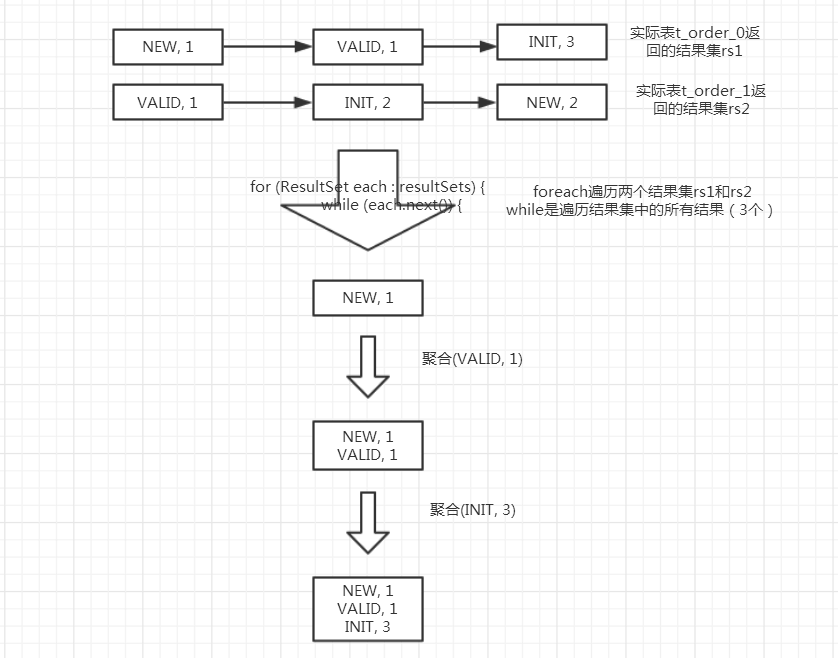
image.png
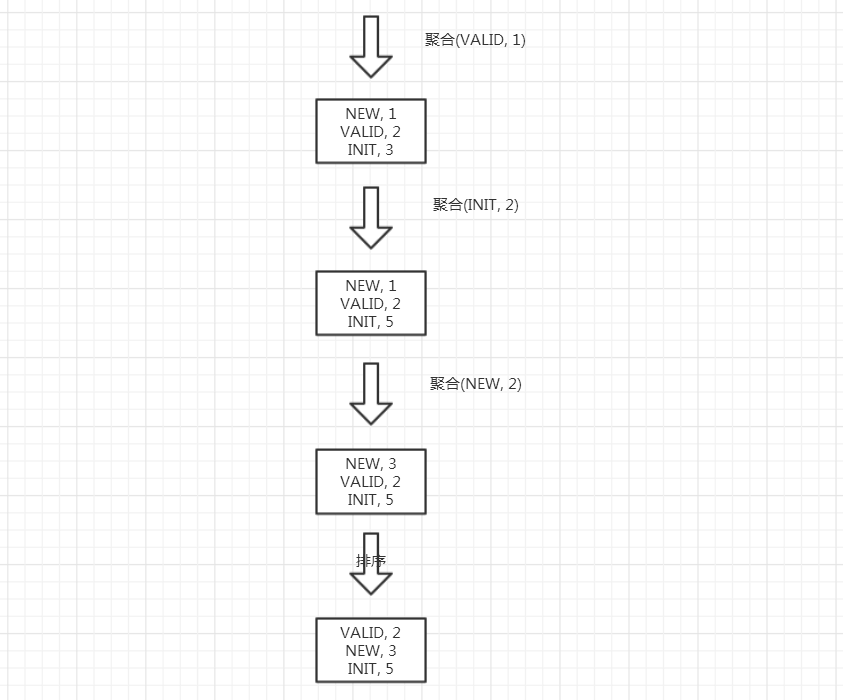
image.png
总结
正如GroupByMemoryResultSetMerger的名字一样,其实现原理是把所有结果加载到内存中,在内存中进行计算,而GroupByMemoryResultSetMerger是流式计算方法,并不需要加载所有实际表返回的结果到内存中。这样的话,如果SQL返回的总结果数比较多,GroupByMemoryResultSetMerger的处理方式就可能会撑爆内存;这个是使用sharding-jdbc一个非常需要注意的地方;
作者:阿飞的博客
来源:https://www.jianshu.com/p/a8e03213b5b6
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫