
机器学习web服务化实战一次吐血的服务化之路
背景
在公司内部,我负责帮助研究院的小伙伴搭建机器学习web服务,研究院的小伙伴提供一个机器学习本地接口,我负责提供一个对外服务的HTTP接口。
说起人工智能和机器学习,python是最擅长的,其以开发速度快,第三方库多而广受欢迎,以至于现在大多数机器学习算法都是用python编写。但是对于服务化来说,python有致命的问题:很难利用机器多核。由于一个python进程中全局只有一个解释器,故多线程是假的,多个线程只能使用一个核,要想充分利用多核就必须使用多进程。此外由于机器学习是CPU密集型,其对多核的需求更为强烈,故要想服务化必须多进程。但是机器学习服务有一个典型特征:服务初始化时,有一个非常大的数据模型要加载到内存,比如我现在要服务化的这个,模型加载到内存需要整整8G的内存,之后在模型上的分类、预测都是只读,没有写操作。所以在多进程基础上,也要考虑内存限制,如果每个进程都初始化自己的模型,那么内存使用量将随着进程数增加而成倍上涨,如何使得多个进程共享一个内存数据模型也是需要解决的问题,特别的如何在一个web服务上实现多进程共享大内存模型是一个棘手的问题。
首先,我们来看看如何进行web服务化呢?我使用python中广泛利用的web框架:Flask + gunicorn。Flask + gunicorn我这里面认为大伙都用过,所以我后面写的就省略些,主要精力放在遇到的问题和解决问题的过程。
实现方式1:每个进程分别初始化自己的模型
为此我编写了一个python文件来对一个分类模型进行服务化,文件首先进行模型初始化,之后每次web请求,对请求中的数据data利用模型进行预测,返回其对应的标签。
#label_service.py
# 省略一些引入的包
model = Model() #数据模型
model.load() #模型加载训练好的数据到内存中
app = Flask(__name__)
class Label(MethodView):
def post(self):
data = request.data
label = model.predict(data)
return label
app.add_url_rule('/labelservice/', view_func=Label.as_view('label'), methods=['POST','GET'])
利用gunicorn进行启动,gunicorn的好处在于其支持多进程,每个进程可以独立的服务一个外部请求,这样就可以利用多核。
gunicorn -w8 -b0.0.0.0:12711 label_service:app
其中:
-w8 意思是启动8个服务进程。
满心欢喜的启动,但是随即我就发现内存直接爆掉。前面说过,我的模型加载到内存中需要8个G,但是由于我启动了8个工作进程,每个进程都初始化一次模型,这就要求我的机器至少有64G内存,这无法忍受。可是,如果我就开一个进程,那么我的多核机器的CPU就浪费了,怎么办?
那么有没有什么方法能够使得8个工作进程共用一份内存数据模型呢? 很遗憾,python中提供多进程之间共享内存都是对于固定的原生数据类型,而我这里面是一个用户自定义的类。此外,模型中依赖的大量的第三方机器学习包,这些包本身并不支持共享内存方式,而且我也不可能去修改它们的源码。怎么办?
gunicorn 进程模型
仔细看了gunicorn的官方文档,其中就有对其工作模型的描述。
- gunicorn主进程:负责fork子进程并监控子进程,根据外部信号来决定是否增加或者减少子进程的数量。
- gunicorn子进程:负责接收web请求并且完成请求计算。
我突发奇想,我可以利用gunicorn父子进程在fork时共享父进程内存空间直接使用模型,只要没有对模型的写操作,就不会触发copy-on-write,内存就不会由于子进程数量增加而成本增长。原理图如下:
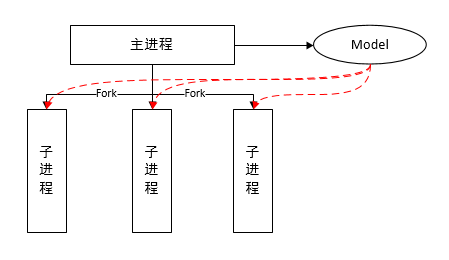

主进程首先初始化模型,之后fork的子进程直接就拥有父进程的地址空间。接下来的问题就是如何在gunicron的一个恰当的地方进行初始化,并且如何把模型传递给Flask。
实现方式2:利用gunicorn配置文件只在主进程中初始化模型
查看gunicorn官方文档,可以在配置文件配置主进程初始化所需的数据,gunicorn保证配置文件中的数据只在主进程中初始化一次。之后可以利用gunicorn中的HOOK函数pre_request,把model传递给flask处理接口。
#gunicorn.conf
import sys
sys.path.append(".") #必须把本地路径添加到path中,否则gunicorn找不到当前目录所包含的类
model = Model()
model.load()
def pre_request(worker, req):
req.headers.append(('FLASK_MODEL', model)) #把模型通过request传递给flask。
pre_request = pre_request
#label_service.py
# 省略一些引入的包
app = Flask(__name__)
class Label(MethodView):
def post(self):
data = request.data
model = request.environ['HTTP_FLASK_MODEL'] #从这里取出模型,注意多了一个HTTP前缀。
label = model.predict(data)
return label
app.add_url_rule('/labelservice/', view_func=Label.as_view('label'), methods=['POST','GET'])
启动服务:
gunicorn -c gunicorn.conf -w8 -b0.0.0.0:12711 label_service:app
使用 -c 指定我们的配置文件。
启动服务发现达到了我的目的,模型只初始化一次,故总内存消耗还是8G。
这里面提醒大家,当你用top看内存时,发现每个子进程内存大小还是8G,没有关系,我们只要看本机总的剩余内存是减少8G还是减少了8*8=64G。
到此,满心欢喜,进行上线,但是悲剧马上接踵而来。服务运行一段时间,每个进程内存陡增1G,如下图是我指定gunicorn进程数为1的时候,实测发现,如果启动8个gunicorn工作进程,则内存在某一时刻增长8G,直接oom。

到此,我的内心是崩溃的。不过根据经验我推测,在某个时刻某些东西触发了copy-on-write机制,于是我让研究院小伙伴仔细审查了一下他们的模型代码,确认没有写操作,那么就只可能是gunicorn中有写操作。
接下来我用蹩脚的英文在gunicorn中提了一个issue:https://github.com/benoitc/gunicorn/issues/1892 ,大神立刻给我指出了一条明路,原来是python的垃圾收集器搞的鬼,详见:https://bugs.python.org/issue31558 , 因为python的垃圾收集会更改每个类的 PyGC_Head,从而它触发了copy-on-write机制,导致我的服务内存成倍增长。
那么有没有什么方法能够禁止垃圾收集器收集这些初始化好的需要大内存的模型呢?有,那就是使用gc.freeze(), 详见 https://docs.python.org/3.7/library/gc.html#gc.freeze 。但是这个接口在python3.7中才提供,为此我不得不把我的服务升级到python3.7。
实现方式3:python2.7升级到python3.7后使用gc.freeze()
升级python是一件非常痛苦的事情,因为我们的代码都是基于python2.7编写,许多语法在python3.7中不兼容,特别是字符串操作,简直恶心到死,只能一一改正,除此之外还有pickle的不兼容等等,具体修改过程不赘述。最终我们的服务代码如下。
#gunicorn.conf
import sys
import gc
sys.path.append(".") #必须把本地路径添加到path中,否则gunicorn找不到当前目录所包含的类
model = Model()
model.load()
gc.freeze() #调用gc.freeze()必须在fork子进程之前,在gunicorn的这个地方调用正好合适,freeze把截止到当前的所有对象放入持久化区域,不进行回收,从而model占用的内存不会被copy-on-write。
def pre_request(worker, req):
req.headers.append(('FLASK_MODEL', model)) #把模型通过request传递给flask。
pre_request = pre_request
上线之后观察到,我们单个进程内存大小从8个G降低到6.5个G,这个推测和python3.7本身的优化有关。其次,运行一段时间后,每个子进程内存缓慢上涨500M左右后达到稳定,这要比每个子进程突然增加1G内存(并且不知道是否只突增一次)要好的多。
使用父子进程共享数据后需要进行预热
当使用gunicorn多进程实现子进程与父进程共享模型数据后,发现了一个问题:就是每个子进程模型的第一次请求计算耗时特别长,之后的计算就会非常快。这个现象在每个进程拥有自己的独立的数据模型时是不存在的,不知道是否和python的某些机制有关,有哪位小伙伴了解可以留言给我。对于这种情况,解决办法是在服务启动后预热,人为尽可能多发几个预热请求,这样每个子进程都能够进行第一次计算,请求处理完毕后再上线,这样就避免线上调用方长时间hang住得不到响应。
结语
到此,我的服务化之路暂时告一段落。这个问题整整困扰我一周,虽然解决的不是很完美,但是对于我这个python新手来说,还是收获颇丰。也希望我的这篇文章能够对小伙伴们产生一些帮助。
作者:haolujun
来源:https://www.cnblogs.com/haolujun/p/9778939.html
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫