
10-数据结构+算法(第10篇)叉堆“功夫熊猫”的速成之路
引言
上一篇文章《菜鸟也能“种”好二叉树!》提到:树是一种分层分类的数据结构,用途是查找和排序。而与查找和排序密切相关的就是求最值(最大值或者最小值)。今天我们就来介绍一个与最值相关的数据结构——二叉堆。
尽管网上或者相关的算法书均有对二叉堆算法的介绍,但大部分只停留在how的阶段,并未对一些关键细节进行why的深究。比如:
- 为什么二叉堆的算法都使用数组作为数据结构,而不是链表?
-
为什么要引入二叉堆的调整算法来构造堆?相对于插入法构造堆,为什么更优?
-
为什么不论是调整法还是插入法来构造堆,都是自底向上进行遍历,而不是自顶向下?
-
采用调整法来构造堆,为什么时间复杂度是O(N)?
本文旨在填补这个空白,“授人鱼更授人以渔”,让你真正精通二叉堆,成为此领域的“功夫熊猫”!


二叉堆是个什么鬼
二叉堆其实就是一种特殊的完全二叉树,它实际上就是在完全二叉树的定义上增加了一条规则:
若每个节点都比它的两个子节点的值大,那么这个完全二叉树就是一个大顶堆;
若每个节点都比它的两个子节点的值小,那么这个完全二叉树就是一个小顶堆。
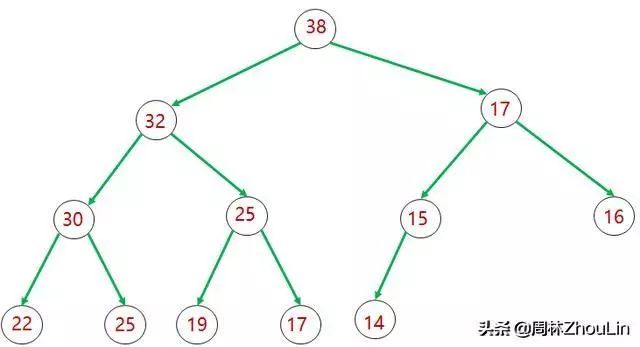
图1 大顶堆
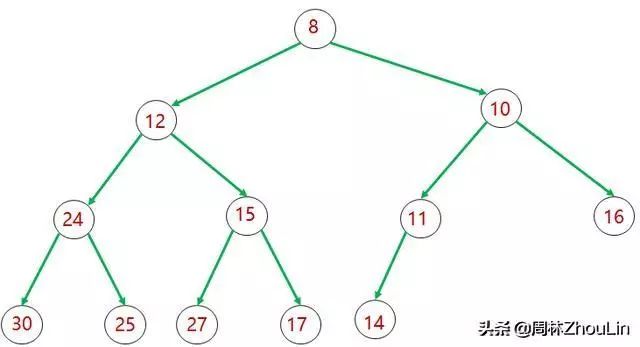
图2 小顶堆
二叉堆有什么鬼用
根据上面大顶堆的定义,求一组元素的最大值,只要我们能把这组元素按照大顶堆的形式组织起来,那么根节点就是最大值所在的节点。
同理,求一组元素的最小值,只要按照小顶堆的形式组织起来,那么根节点就是最小值所在节点。
如何描述二叉堆
了解了堆有什么用之后,接下来就要讲如何来描述一个堆——换言之,堆的数据结构如何表达?
既然堆本质是完全二叉树,所以堆也可以像完全二叉树那样,用链表或者数组来表达。唯一的区别是:在用链表或者数组来表达时,要时刻保证当前节点的值比两子节点的值要大(或者小)。那么实操时,如何做到这一点呢?
最朴素的想法就是:先对所有的元素进行排序,然后按照顺序依次从根节点位置往下填。
且不谈这个方法要涉及到全排序,耗时耗空间,它最大的问题是:
你都排好序了,那么最值也就知道了,还跑回来构造个啥堆啊?
那么还有什么好方法呢?想想我们还有什么武器没有使用过?对了,还有在《再不会"降维打击"你就Out了!》一文中提到的“核武器”——递归没有使用呢!
递归构造二叉堆
为了简化起见,下面我们以大顶堆为例,小顶堆可以对称推导。
根据《再不会"降维打击"你就Out了!》一文中讲到的递归套路:
先分析规模因子:很明显规模因子就是元素个数
再分析状态转移函数:假设构造规模为n-1的堆的算法是f(n-1),那么构造规模为n的堆,就相当于在f(n-1)的堆上插入第n个节点。如果设插入算法是g,那么状态转移的表达式:
f(n)=g(f(n-1))
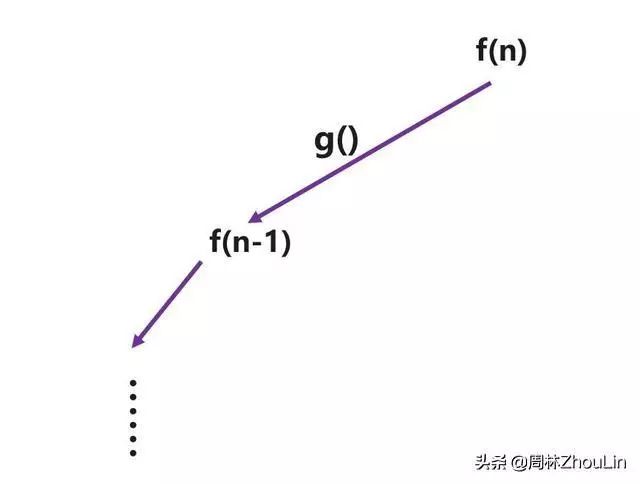
图3 递归构造二叉堆
接下来看看初始问题状态:显然就是只有一个元素的情况。
在看看边界问题状态:显然就是一个元素都没有的情况。
还是根据《神力加身!动态编程》中讲到的老套路,看看能否用动态规划来优化递归。
该问题的递归展开树如下:
这种简单结构应用自底向上的动态规划不要太爽:)
先用插入算法g()生成一个节点的堆、再叠加用一次g()生成两个节点的堆,以此类推,直到生成覆盖所有节点的堆。
经过上面的分析,可以看出:递归构造堆的核心在于堆的插入算法。
链表 vs. 数组
既然要向已有堆插入新节点,那么首先要定位插入的位置。
最朴素的想法就是:从根节点开始,逐层依次比较各节点,精确找到插入的位置。
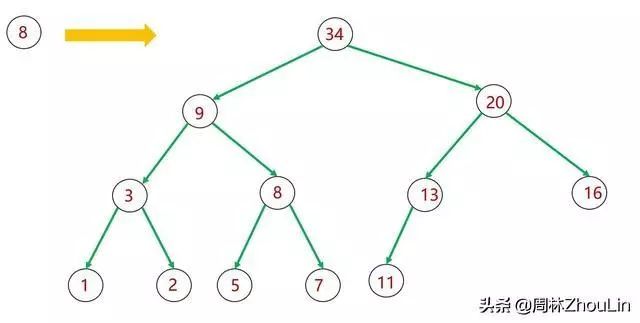
图4 插入新节点——广度遍历二叉堆
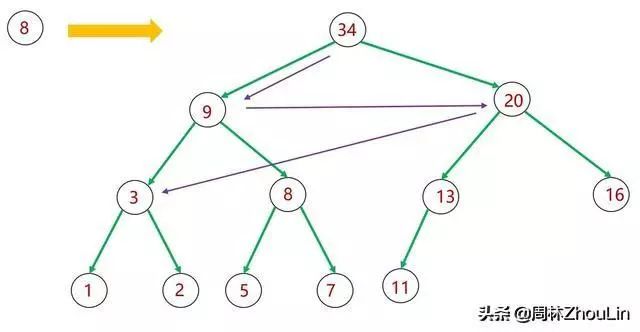
图5 插入新节点——广度遍历二叉堆
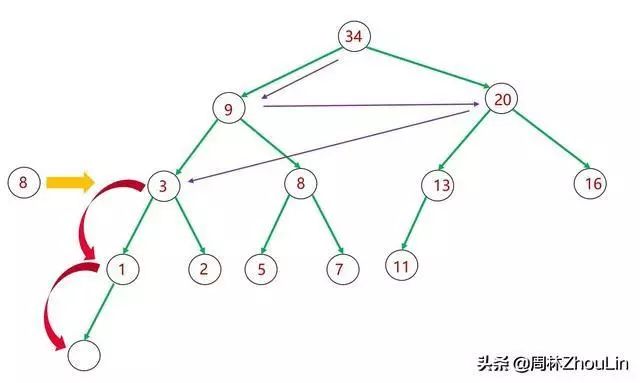
图6 插入新节点——广度遍历二叉堆
这其实就是所谓的“广度优先遍历算法”。
插入之后,原有节点的坑被新元素占了,它就只能去占子节点的坑了,这种“霸占”行为逐层传导下去,直到原叶子节点只能委屈求全再向下挪一层——“打不过你,我跑总可以了吧”。
看到这里似乎一切都很美好,但是这里有两个问题:
第一:在图6的广度遍历中,如何从值为20的节点跳到值为3的节点?
如果整棵树是用链表形式来存储各节点的话:
由于值为3的节点不是值为20的节点的子节点,从值为20的节点根本无法直接得知值为3的节点的位置,除非回溯到值为9的节点,用值为9的节点的子节点链接才能抵达值为3的节点。根据在《史上最猛之递归屠龙奥义》一文中学到的知识,这个回溯需要用到堆栈。不仅需要额外的存储空间,而且也耽误时间。
第二:如果只是逐一下挪,那么产生的新二叉树,可能都不是一棵完全二叉树了(如图5所示),也就不符合堆的定义。此时可能还需要进行水平调整。想想这个过程就很复杂。
那么往下挪会破坏完全二叉树的结构,是否可以向上挪呢?
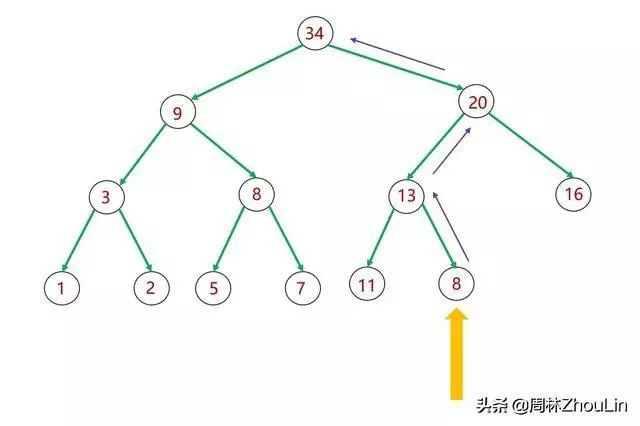
图7 二叉堆的后插
如图7所示,如果将新节点插入到完全二叉树的“尾部”(值为13的节点),那么向上逐层比较、进行必要位置调换,就可以完美避开上述的第二个问题。
这个新方法的关键在于:
(1)识别出完全二叉树的“尾部”位置
(2)向上回溯的链接信息
对于第(2)点,采用双向链表就可以解决;但是对于第(1)点就比较麻烦。
除了上图这种一般情况外,还有下图这种满二叉树的情况。不同的情况,“尾部”位置并不是固定的,有时在靠近树的右边,有时在靠近树的左边。
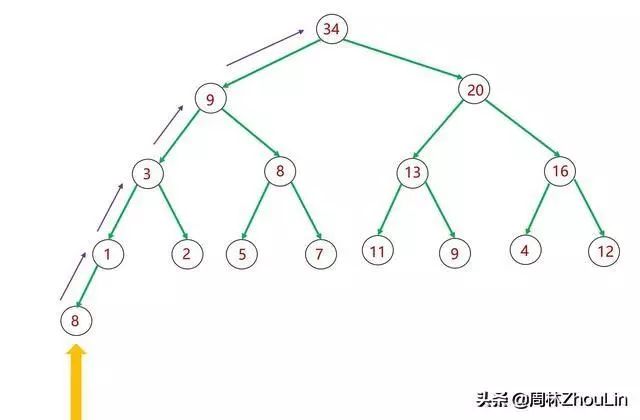
图8 二叉堆的后插
因为没有现成的数据结构或者特征能标识“尾部”位置,需要开发相应算法来解决。这个算法我们留在下一篇文章详细来讲。
综上所述,用链表来描述堆不方便。
如果整棵树是用数组形式来存储各节点的话,看看解决上面两个问题是否方便。
在图7所示的一般完全二叉树中,除开待插入的值为8的节点,节点总数为12。插入位置是值为13的节点位置。用数组存储时,值为13的节点是数组的第6号元素。6=12/2。
在图8所示的满二叉树中,除待插入的值为8的节点之外,节点总数为15。插入位置是值为1的节点位置。用数组存储时,值为1的节点是数组的第8号元素。8=15/2的值向上取整。
看出什么规律了吗?
无论是一般完全二叉树还是满二叉树,插入的位置都可以由数组元素总数唯一决定!
这个规律其实隐含在上一篇文章《菜鸟也能“种”好二叉树!》的推论5.2.1中:
数组第n号元素所代表的节点,它的左子节点是数组的第(2n+1)号元素,它的右子节点是数组的第2(n+1)号元素
用floor_round(a)表示对a向下取整的话,那么把上面推论反过来用就是:
数组第n号元素所代表的节点,它的父节点是数组的第floor_round(n/2)号元素。
当n可被2整除时,说明第n号元素所代表的节点是其父节点的左孩子;
当n不被2整除时,说明第n号元素所代表的节点是其父节点的右孩子。
这样,我们就完美地解决了问题(1)。
至于问题(2),对数组就更不是问题了——还记得《小白也能玩转数组和链表啦!》一文中的比喻吗?数组就是电梯,电梯既可以上也可以下!
<section class="" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
堆的插入算法
</section>
看到这里,相信最大堆的插入算法已经一目了然了:
注意:为了方便地利用上述父子元素的序号关系,我们把数组的第一个下标空出来不放实际元素,只作为一个临时单元使用。
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
import java.util.ArrayList;class BinaryHeap {private ArrayList arrayNodes;public BinaryHeap() {this.arrayNodes=new ArrayList(1);}public void heapInsert(int newItem) {int count=this.arrayNodes.size();if(count<=1) {this.arrayNodes.add(newItem);return;}int i=count>>1;this.arrayNodes.add(newItem);int j=count;do {this.arrayNodes.set(0,this.arrayNodes.get(i));if((int)(this.arrayNodes.get(0))<newItem) {this.arrayNodes.set(i, newItem);this.arrayNodes.set(j, this.arrayNodes.get(0));j=i;i=i>>1;}else {break;}}while(i>0);}}
</section>
有了堆的插入算法,根据前面的分析,循环对节点调用heapInsert()就可以生成完整的堆。
<section class="" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
堆的构造算法的时间复杂度
</section>
显然,有多少个元素,就需要调用多少次heapInsert()。
heapInsert()本身的时间复杂度f与while循环执行的次数有关。很显然,最坏情况下,while循环的次数就是堆(完全二叉树)的高度H。
根据上一篇《菜鸟也能“种”好二叉树!》中讲到的二叉树的性质:
H=up_round(log(M+1))=O(logM),其中M是当前堆中的节点总数。
设最终堆的节点总数为N,则M从1变化到N。
设堆的构造算法的时间复杂度为K,则根据《KO!大O——时间复杂度》一文的推论3.1有:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
K=O(log1)+O(log2)+……+O(logN)=O(log1+log2+……+logN)=O(log1x2x……xN)=O(logN!)<O(logN^N)=O(NlogN)(式1)
</section>
<section class="" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
还能更快吗?
</section>
整个算法的主体是heapInsert(),对它分析如下:
(1)每个新节点都要挨个与“尾部”到堆顶这条路径上的每个节点做比较;
(2)每个节点必然和它子树中的所有节点进行过比较
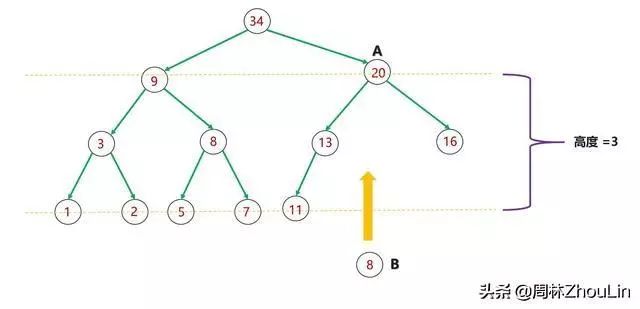
图9 二叉堆节点插入算法分析
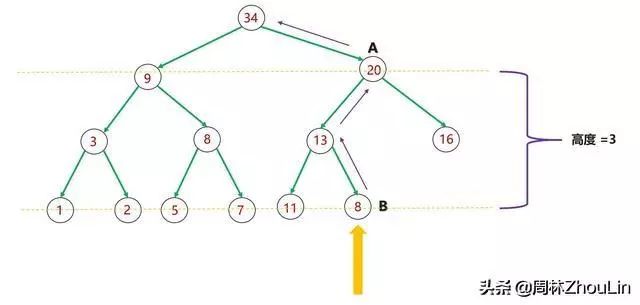
图10 二叉堆节点插入算法分析
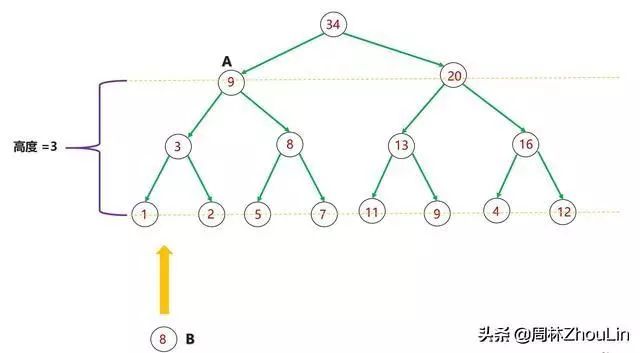
图11 二叉堆节点插入算法分析
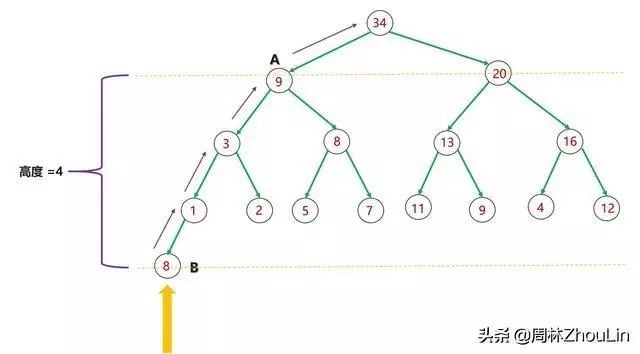
将节点A被比较的总次数记为C(A),则:
<pre style="margin: 1em 0px; padding: 12px 10px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-indent: 0px; text-transform: none; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; -webkit-tap-highlight-color: transparent; font-family: Consolas, Menlo, Courier, monospace; font-size: 16px; white-space: pre-wrap; line-height: 1.5; color: rgb(153, 153, 153); background: rgb(244, 245, 246); border-width: 1px; border-style: solid; border-color: rgb(232, 232, 232); text-align: start;">C(A)=A的子树节点总数M(A)(式2)
</pre>
显然假设最终二叉堆由n个节点构成,则总比较次数N为:
<pre style="margin: 1em 0px; padding: 12px 10px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-indent: 0px; text-transform: none; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; -webkit-tap-highlight-color: transparent; font-family: Consolas, Menlo, Courier, monospace; font-size: 16px; white-space: pre-wrap; line-height: 1.5; color: rgb(153, 153, 153); background: rgb(244, 245, 246); border-width: 1px; border-style: solid; border-color: rgb(232, 232, 232); text-align: start;">N=C(A1)+C(A2)+…+C(An)
=M(A1)+M(A2)+…+M(An)(式3)
</pre>
显然这个过程是应该被优化的——如果每个节点不用和它子树中的所有节点进行比较,算法速度不就提升了吗?
那么如何减少这个比较次数呢?
上面算法是将节点一个一个地往数组里添加调整,那么如果把所有节点一次性全部扔进数组进行调整,是否就可以达到这个目的呢?
全部扔进数组后,相当于一次性创建了一个完全二叉树,现在开始对其进行调整。
调整动作涉及两方面:
(1)调整的方向
(2)要调整的节点
<section class="" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
自顶向下调整 vs. 自底向上调整
</section>
调整方向到底采用自顶向下还是自底向上呢?
根据《神力加身!动态编程》一文所讲到的,为了利用动态规划,最好采用自底向上。
为了证明这个预判是正确的,我们作如下分析。
假设我们采用自顶向下的调整策略,那么会遭遇下图13~图15所示的“回溯”问题,而破坏递归下降的过程。
如下图所示,如果子树里有值非常大的节点,那么这个节点最终不仅仅是取代其父节点位置,它还要“篡位”祖父节点甚至曾祖父节点!
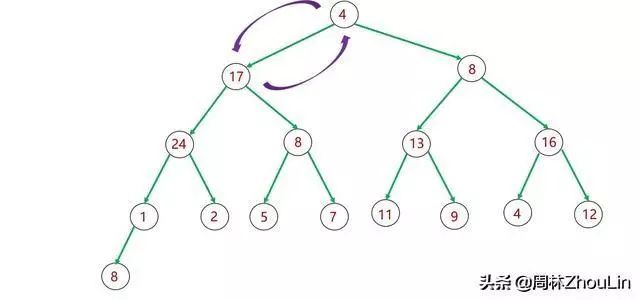
图13 二叉堆自顶向下调整分析

图14 二叉堆自顶向下调整分析
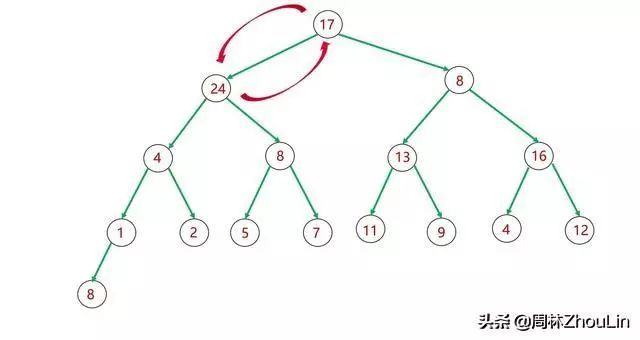
图15 二叉堆自顶向下调整分析
一旦发生上述的“回溯”,那么就会带来两方面问题:
(1)算法逻辑的复杂性增加;
(2)根据《史上最猛之递归屠龙奥义》一文所提到的,回溯就要用堆栈来防止“失忆”,这会增加存储的开销。
自顶向下的递归式调整算法如下:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
public void heap_fixdown_recursive(int index, int[] arrayNodes) {if(arrayNodes==null) {return;}int count=arrayNodes.length-1;if(index<=0||index>count) {return;}int left_index=index<<1;int right_index=left_index+1;boolean left_valid=(left_index<=count)?true:false;boolean right_valid=(right_index<=count)?true:false;heap_fixdown_recursive(right_index, arrayNodes);if(right_valid) {heap_fixdown_recursive(left_index, arrayNodes);}int current=arrayNodes[index];int left=left_valid?arrayNodes[left_index]:0;int right=right_valid?arrayNodes[right_index]:0;int max=left_valid?left:0;if(right_valid&&right>max) {max=right;}if(left_valid) {if(max>current) {if(max==left) {arrayNodes[left_index]=current;arrayNodes[index]=max;heap_fixdown_recursive(left_index, arrayNodes);}else if(right_valid){arrayNodes[right_index]=current;arrayNodes[index]=max;heap_fixdown_recursive(right_index, arrayNodes);}}}}public void heapBuild_recursive(int[] list_nodes) {if(list_nodes==null) {return;}if(list_nodes.length<=1) {return;}heap_fixdown_recursive(1, list_nodes);}
</section>
二叉堆调整算法
既然有了上述的递归算法,那么按照《史上最猛之递归屠龙奥义》一文介绍的“人肉消除递归”套路,可以轻松写出对应的非递归算法。
下面我们换个角度、“一题多解”,看看能不能直接用动态规划来推出非递归算法。
自底向上调整关键就是以下几点:
(1)自底向上,先将父节点的左右子树调整成堆;
(2)再来比较父节点与其孩子的值:如果当前父节点的值小于孩子的值,那么就交换两者的位置,将父节点下推。
先来分析一下自底向上调整的轨迹:
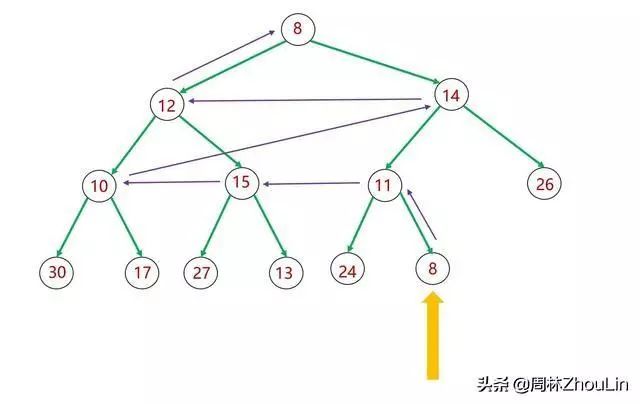
图16 二叉堆自底向上调整算法
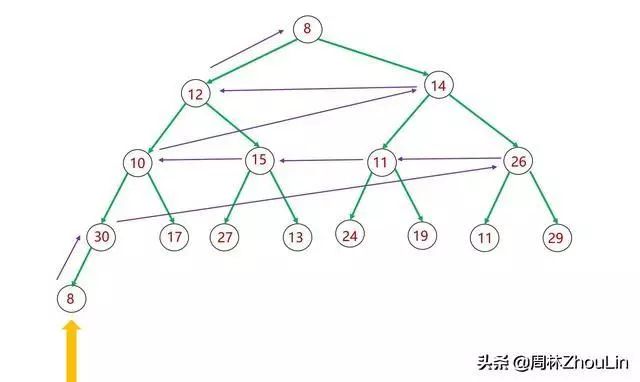
图17 二叉堆自底向上调整算法
上图中紫色箭头表示向上调整的轨迹。可以看出:
(1)整个轨迹分为两个维度——垂直维度和水平维度。
垂直维度:方向向上。紫色箭头表示向上调整到父节点一层;
水平维度:方向向左。紫色箭头表示向左调整到相邻的兄弟节点。
(2)每一层水平方向的遍历距离=对应父子节点在数组中的下标之差。
(3)由于对当前节点下推之后,要能返回到之前的位置继续向上调整,所以需要记忆返回位置。这个已经老生常谈多次,用堆栈保留即可。其实从《史上最猛之递归屠龙奥义》一文中讲到的递归消除技巧也可以推导出来这个结论:
画出上面递归式二叉堆调整算法的递归展开树如下,递归实现体中有3个子递归调用:
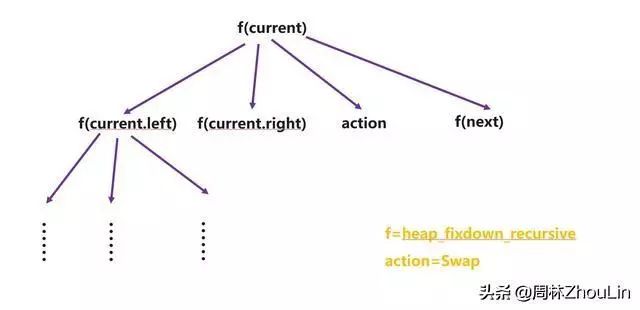
图18 递归展开树
根据《史上最猛之递归屠龙奥义》一文中讲到的:为了区别子递归调用返回时的“微观地址”,需要增加标记保存到堆栈中。
由前一章节的结论:父节点在数组中的下标=子节点在数组中的下标/2。
根据上面的分析(1)和(2),可以得出如下的堆调整算法与优化后的堆构造算法:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
public void heap_fixdown_nonrecursive(int[] arrayNodes) {if(arrayNodes==null) {return;}int count=arrayNodes.length;if(count<=1) {return;}int index=count-1;while(index>1) {int layer_cursor=index>>1;while(index>layer_cursor) {//swap father and child if the value of child is biggerint father_index=index>>1;int left_index=father_index<<1;int right_index=left_index+1;while(left_index<count) {int left=arrayNodes[left_index];int father=arrayNodes[father_index];int max=left;int push_down_start_index=-1; if(right_index<count) {int right=arrayNodes[right_index];if(right>max) {max=right;}}if(max>father) {if(max==left) {arrayNodes[left_index]=father;arrayNodes[father_index]=max; push_down_start_index=left_index;}else {arrayNodes[right_index]=father;arrayNodes[father_index]=max; push_down_start_index=right_index;}}//Push down father nodeif(push_down_start_index!=-1) {father_index=push_down_start_index;left_index=father_index<<1;right_index=left_index+1;}else {break;} }father_index=index>>1;index-=2;}index=layer_cursor;} }public void heapBuild_nonrecursive(int[] list_nodes) {if(list_nodes==null) {return;}if(list_nodes.length<=1) {return;}heap_fixdown_nonrecursive(list_nodes);}
</section>
<section class="" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
通过堆调整算法来构造堆的时间复杂度
</section>
从上面的堆调整算法可以看出,在最坏情况下:
高度为h的每个节点k都被进行了如下操作:
- 左右孩子做了一次比较
-
该节点与孩子中最大的那个做了一次比较
-
交换父子节点位置
-
下推到叶子节点
其中第1步和第2步都是1个简单的比较语句,第3步涉及一次交换,第4步共需要做(H-h)次交换(设H是整个二叉堆的高度),所以对于节点k的时间开销为O(H-h)。
设高度h的节点数目为m,则:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
h<H时:m=2^(h-1)h=H时:1<=m<=2^(h-1)(式4)
</section>
高度h的所有节点的构建时间开销为
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
mxO(H-h)=O(m(H-h))(式5)
</section>
若设M=叶子节点总数,则M<=2^(H-1),整个二叉堆构建的时间复杂度K为:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
K=O(2^(1-1)x(H-1))+O(2^(2-1)x(H-2))+...O(2^(h-1)x(H-h))+...+O(Mx(H-H))<=O(2^(1-1)x(H-1))+O(2^(2-1)x(H-2))+...O(2^(h-1)x(H-h))+...+O(2^(H-1)x(H-H))=O(2^(1-1)x(H-1)+2^(2-1)x(H-2)+...+2^(H-1)x(H-H))=O(H(2^0+2^1+...+2^(H-1))-(1x2^0+2x2^1+...+Hx2^(H-1)))(式6)
</section>
令s=2^0+2^1+…+2^(H-1),t=1×2^0+2×2^1+…+Hx2^(H-1),则上式简记为:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
K<=O(Hxs-t)(式7)
</section>
s是一个等比数列求和,其值:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
s=2^H-1(式8)
</section>
t式右边可写成如下形式:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
[1^2^0+1x2^1+1x2^2+...+1x2^(H-1)]+[1x2^1+1x2^2+...+1x2^(H-1)]+[1x2^2+...+1x2^(H-1)]+...+[1x2^(H-1)]
</section>
每个中括号里都是一个等比数列,其值分别是2^H-2^0,2^H-2^1,…,2^H-2^(H-1),所以:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
t=(2^H-2^0)+(2^H-2^1)+...+(2^H-2^(H-1))=(2^H+2^H+...+2^H)-(2^0+2^1+...+2^(H-1))
</section>
上式第一个括号里共有H个2^H,其值等于Hx2^H;
上式第二个括号里是一个等比数列,其值等于2^H-1。所以:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
t=Hx2^H-(2^H-1)=1-2^H+Hx2^H(式9)
</section>
将式8、式9代入式7可得:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
K<=O(sH-t)=O(Hx(2^H-1)-(1-2^H+Hx2^H)=O(2^H-H-1)(式10)
</section>
根据《菜鸟也能“种”好二叉树!》的5.1章节的结论:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
H<=logN(N代表二叉堆的节点总数)(式11)
</section>
代入式10可得:
<section data-mpa-preserve-tpl-color="t" data-mpa-template="t" class="" mpa-preserve="t" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
K<=O(2^logN-logN-1)=O(N-logN-1)=O(N)(式12)
</section>
这表示:通过堆调整算法来构造堆的时间复杂度为O(N),仅仅与元素数目线性相关。
<section class="" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
Top N问题
</section>
求最大值时,构造大顶堆,堆顶就是最大值;
求最小值时,构造小顶堆,堆顶就是最小值。
求次大(小)值时,可以将堆顶元素拿走,再把最后一个元素换到堆顶,从堆顶进行调整,调整结束后的堆顶就是次大(小)值。
依次类推,可以求出Top N元素。
<section class="" mpa-from-tpl="t" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(51, 51, 51); font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: normal; letter-spacing: 0.544px; orphans: 2; text-align: justify; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);">
One More Thing
</section>
笔者原创连载《算法素颜》这个系列的目的就是:打消一些朋友对算法高深莫测的印象,还原算法的本质。“素颜”一词源自日语,意为“本质、真面目”。
现在很多朋友学习算法的动机在于求职应聘找高薪,为了追求短时间的速成,大量地刷题。其实这并不是真正提高算法素养的正道。
这种方式相当于将自己退化成机器,采用机器学习的强化学习算法——利用海量的刷题来“喂数据”。但是人相对于机器,高明之处在于通过少量样本、进行深度思考,直接发现本质的规律,进而举一反三、扩大应该用边界,效率高下之分立竿见影。
后面笔者会写一篇文章,详细来讲讲学习算法的“正确姿势”。
希望读者能够给小编留言,也可以点击[此处扫下面二维码关注微信公众号](https://www.ycbbs.vip/?p=28 "此处扫下面二维码关注微信公众号")
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫