TiDB Binlog 简介
TiDB Binlog 是一个用于收集 TiDB 的 binlog,并提供准实时备份和同步功能的商业工具。
TiDB Binlog 支持以下功能场景:
- 数据同步:同步 TiDB 集群数据到其他数据库
- 实时备份和恢复:备份 TiDB 集群数据,同时可以用于 TiDB 集群故障时恢复
TiDB Binlog 整体架构
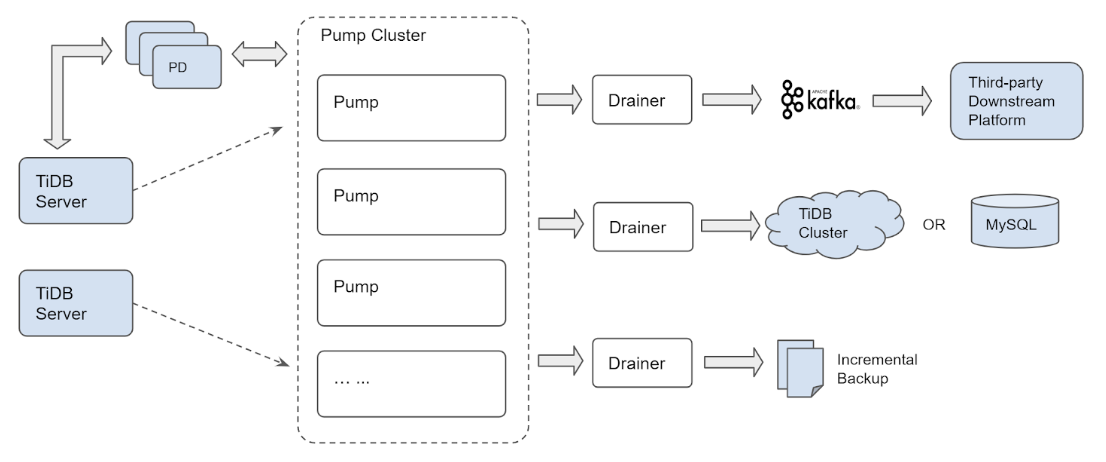
TiDB Binlog 集群主要分为 Pump 和 Drainer 两个组件,以及 binlogctl 工具:
Pump
Pump 用于实时记录 TiDB 产生的 Binlog,并将 Binlog 按照事务的提交时间进行排序,再提供给 Drainer 进行消费。
Drainer
Drainer 从各个 Pump 中收集 Binlog 进行归并,再将 Binlog 转化成 SQL 或者指定格式的数据,最终同步到下游。
binlogctl 工具
binlogctl 是一个 TiDB Binlog 配套的运维工具,具有如下功能:
- 获取 TiDB 集群当前的 TSO
- 查看 Pump/Drainer 状态
- 修改 Pump/Drainer 状态
- 暂停/下线 Pump/Drainer
主要特性
- 多个 Pump 形成一个集群,可以水平扩容。
- TiDB 通过内置的 Pump Client 将 Binlog 分发到各个 Pump。
- Pump 负责存储 Binlog,并将 Binlog 按顺序提供给 Drainer。
- Drainer 负责读取各个 Pump 的 Binlog,归并排序后发送到下游。
服务器要求
Pump 和 Drainer 都支持部署和运行在 Intel x86-64 架构的 64 位通用硬件服务器平台上。对于开发,测试以及生产环境的服务器硬件配置有以下要求和建议:
| 服务 | 部署数量 | CPU | 磁盘 | 内存 |
|---|---|---|---|---|
| Pump | 3 | 8核+ | SSD,200GB+ | 16G |
| Drainer | 1 | 8核+ | SAS,100GB+(如果输出为本地文件,则使用SSD,并增加磁盘大小) | 16G |
注意事项
- 需要使用 TiDB v2.0.8-binlog、v2.1.0-rc.5 及以上版本,否则不兼容该版本的 TiDB Binlog。
- Drainer 支持将 Binlog 同步到 MySQL、TiDB、Kafka 或者本地文件。如果需要将 Binlog 同步到其他 Drainer 不支持的类型的系统中,可以设置 Drainer 将 Binlog 同步到 Kafka,然后根据 binlog slave protocol 进行定制处理,参考 binlog slave client 用户文档。
- 如果 TiDB Binlog 用于增量恢复,可以设置配置项
db-type="file",Drainer 会将 binlog 转化为指定的 proto buffer 格式的数据,再写入到本地文件中。这样就可以使用 Reparo 恢复增量数据。
关于 db-type 的取值,应注意:
- 如果 TiDB 版本 < 2.1.9,则
db-type="pb"。 - 如果 TiDB 版本 > = 2.1.9,则
db-type="file"或db-type="pb"。 - 如果下游为 MySQL/TiDB,数据同步后可以使用 sync-diff-inspector 进行数据校验。
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「资源」 免费领取我精心整理的前端进阶资源教程
