TiDB-Lightning 简介
TiDB-Lightning 是一个将全量数据高速导入到 TiDB 集群的工具,有以下两个主要的使用场景:一是大量新数据的快速导入;二是全量数据的备份恢复。目前,支持 mydumper 或 CSV 输出格式的数据源。您可以在以下两种场景下使用 Lightning:
- 迅速导入大量新数据。
- 备份恢复所有数据。
TiDB-Lightning 整体架构
TiDB-Lightning 主要包含两个部分:
tidb-lightning(“前端”):主要完成适配工作,通过读取数据源,在下游 TiDB 集群建表、将数据转换成键/值对 (KV 对) 发送到tikv-importer、检查数据完整性等。tikv-importer(“后端”):主要完成将数据导入 TiKV 集群的工作,把tidb-lightning写入的 KV 对缓存、排序、切分并导入到 TiKV 集群。
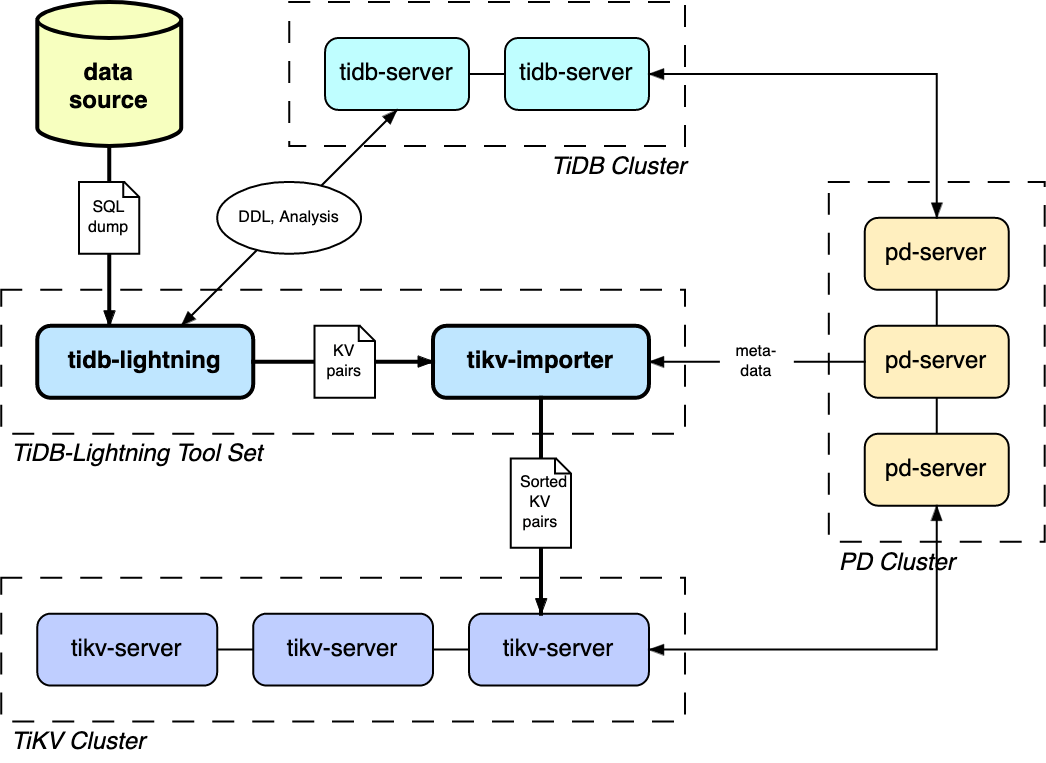
TiDB-Lightning 整体工作原理如下:
- 在导数据之前,
tidb-lightning会自动将 TiKV 集群切换为“导入模式” (import mode),优化写入效率并停止自动压缩 (compaction)。 tidb-lightning会在目标数据库建立架构和表,并获取其元数据。- 每张表都会被分割为多个连续的区块,这样来自大表(200 GB+)的数据就可以用增量方式导入。
tidb-lightning会通过 gRPC 让tikv-importer为每一个区块准备一个“引擎文件 (engine file)”来处理 KV 对。tidb-lightning会并发读取 SQL dump,将数据源转换成与 TiDB 相同编码的 KV 对,然后发送到tikv-importer里对应的引擎文件。- 当一个引擎文件数据写入完毕时,
tikv-importer便开始对目标 TiKV 集群数据进行分裂和调度,然后导入数据到 TiKV 集群。
引擎文件包含两种:数据引擎与索引引擎,各自又对应两种 KV 对:行数据和次级索引。通常行数据在数据源里是完全有序的,而次级索引是无序的。因此,数据引擎文件在对应区块写入完成后会被立即上传,而所有的索引引擎文件只有在整张表所有区块编码完成后才会执行导入。
- 整张表相关联的所有引擎文件完成导入后,
tidb-lightning会对比本地数据源及下游集群的校验和 (checksum),确保导入的数据无损,以及让 TiDB 分析 (ANALYZE) 这些新增的数据,以优化日后的操作。 - 在所有步骤完毕后,
tidb-lightning自动将 TiKV 切换回“普通模式” (normal mode),此后 TiDB 集群可以正常对外提供服务。
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「资源」 免费领取我精心整理的前端进阶资源教程
